当CUDA撞上DLA暗礁:一个DLA死锁引发的蝴蝶效应与安全气囊的诞生
在 Jetson AGX Orin/Orin-X 平台的实际运行中,CUDA 与 DLA 原本各司其职,却因并发而偶发集体“假死”——所有线程在 cudaStreamSynchronize() 阻塞中寸步难行。面对这一似乎无解的死锁暗礁,我从故障复现场景入手,定位到混合推理流中的同步点;随后排除了显存越界、流类型、DLA 降频等常见因素;最终灵感来源于“反向隔离”思路——为 GPU 与 DLA 各自配置独立的 GPU Context,并通过显式的异步拷贝与同步保证数据无缝切换。
本文将以最直接的技术视角——从现象描述、排查方法到“多 Context 安全气囊”实现细节——全流程解读如何在 7×24h 压测中彻底消除死锁,实现并行推理的性能与可靠性双赢。
一、问题现象
1. 偶发死锁
症状描述:单进程内,所有线程在调用 GPU 时集体“假死”——
cudaStreamSynchronize()一直阻塞,tegrastats显示 GPU 占用率维持在某个固定值,不再波动。复现难度:
- 极不稳定:有时运气极差,一周都无法触发;有时运气极好,仅需两小时即复现。
- DLA 与 CUDA 混合推理时尤甚:DLA 推理线程先“提前几毫秒”挂死,其他线程随后也步入停滞。

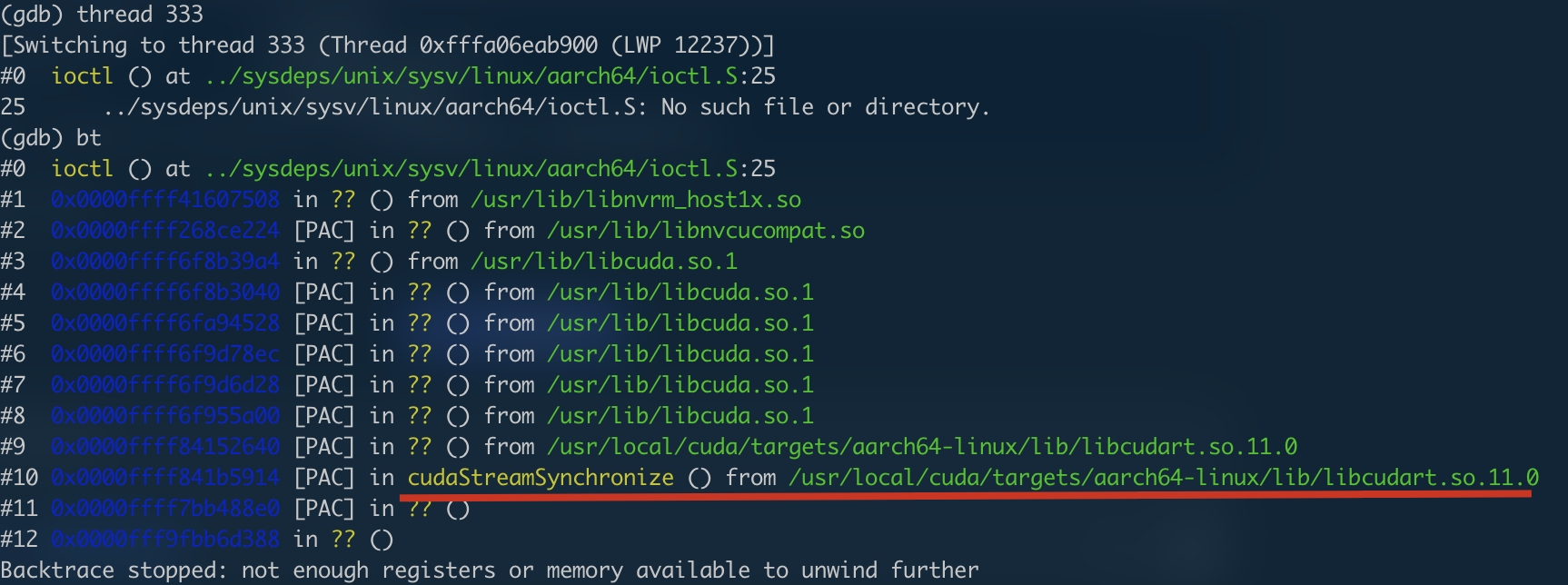
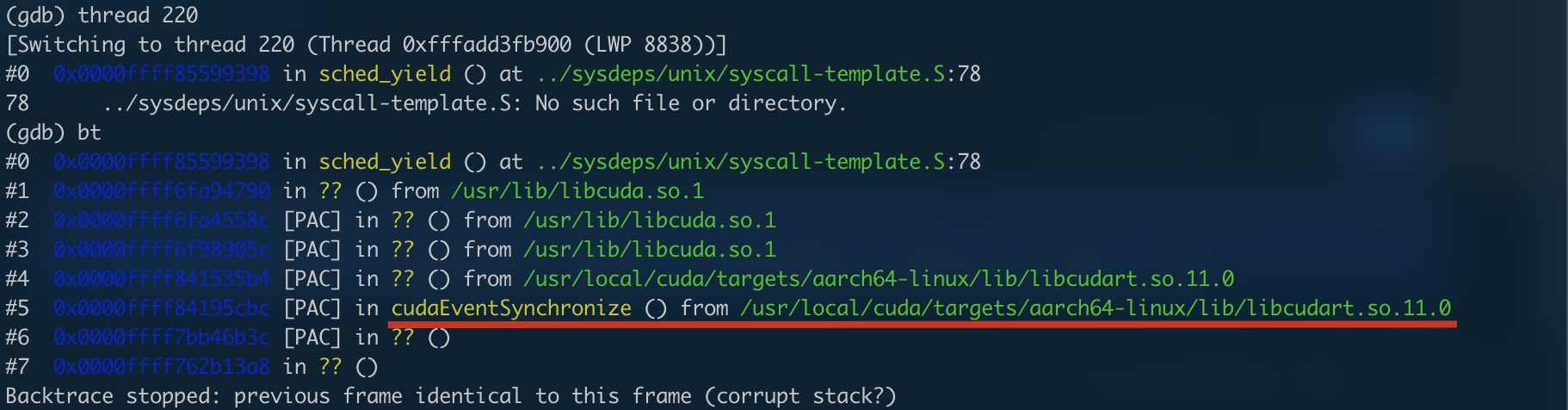
GPU推理线程 与 DLA推理线程 同时卡死
2. 环境特征
- 硬件平台:Jetson AGX Orin 系列(最初使用 AGX Orin,后转至 Orin-X)。
- 推理流程:
- 全部模型均通过 TensorRT 的
enqueueV3()+ CUDA Stream 异步执行; - 前处理同样基于 CUDA Stream;
- 部分子图运行于 DLA,非支持算子回落至 Tensor/Tensor Core。
- 全部模型均通过 TensorRT 的
二、初步排查
1. 定位死锁环节
通过在各关键步骤间插入 cudaStreamSynchronize(),逐步缩小排查范围:
- 前处理 —— 无异常;
- TensorRT
enqueueV3()—— 成功返回; - 自定义 Plugin(HWCBGR → CHWRGB)—— 顺利完成;
- 同步点 —— 在 Plugin 之后的第一次
cudaStreamSynchronize()挂死。
2. 排除思路
显存越界?
- 其中一个模型 A 曾在 2024 年出现过显存越界,但通常显存越界会触发 sticky error 并抛出
illegal memory access而非死锁。
- 其中一个模型 A 曾在 2024 年出现过显存越界,但通常显存越界会触发 sticky error 并抛出
Blocking vs. Non-blocking Stream?
- 初步猜测 DLA 可能依赖于 blocking stream,而我使用的是 non-blocking 版;最终未能证实。
DLA 频率降频?
- 若 DLA 调用低于 2 Hz,会自动释放并重申请资源,导致延迟飙升。
- 提升调用频率后虽解决了降频,但死锁依旧。
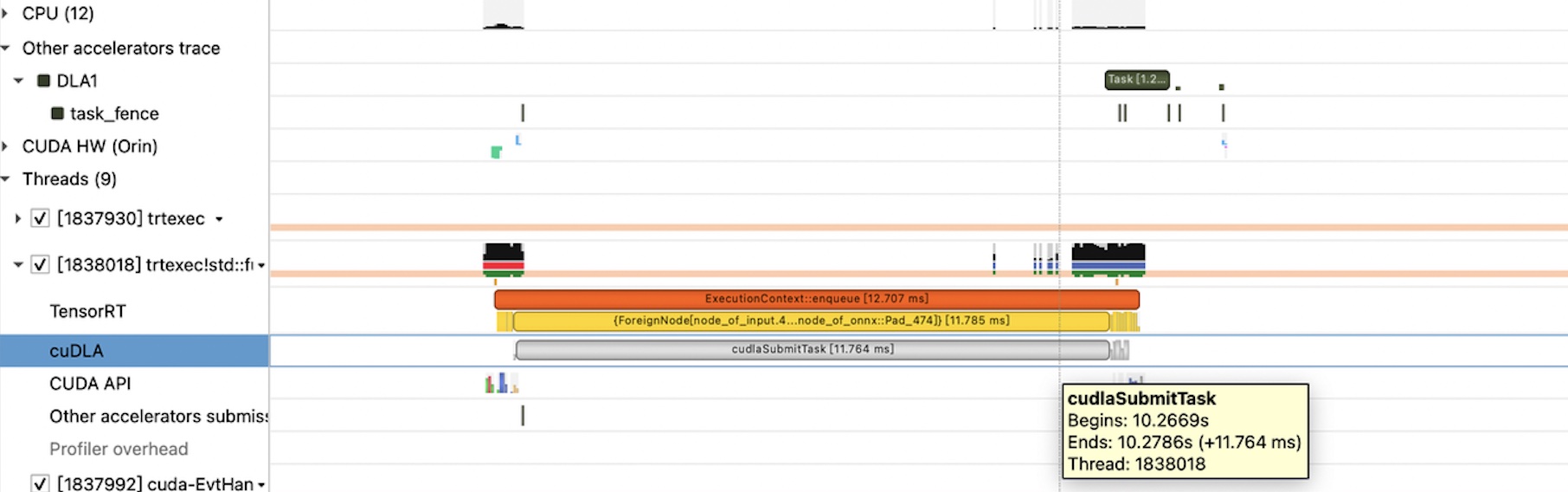
三、环境变更与新线索
1. 从 AGX Orin 到 Orin-X
- 2024 年 3 月,怀疑 AGX Orin DLA 变频机制有问题,遂放弃尝试;
- 2025 年 3 月,转战 Orin-X,DLA 频率稳定——但在并行运行其他 GPU 模型 A 时,依旧触发死锁。
2. 关键“怀疑模型 A”
- 模型 A 曾导致显存越界,虽然在最小化测试环境下并未复现死锁,但在系统中只要与 DLA 并行,死锁概率骤增,然而其余模型并不会导致该问题。
- 单独跑 DLA、单独跑模型 A 均正常,仅并行时“相逢即死锁”。
四、“安全气囊”诞生:多 Context 隔离策略
1. 灵感来源
面试一位候选人提到的 GPU 多进程中间件:
“通过截获多进程的 GPU 请求,在后端融合 context,实现时分复用,从而提升GPU利用率。”
虽然该方案与我单进程场景相悖,却激发了一个思路——反其道而行之:既然单 context 并行 DLA + GPU 会死锁,何不为它们分别提供独立 context?
2. 实施要点
- 上下文划分
- Orin 系列拥有 2 个 DLA 引擎 + 1 个 GPU,引擎间资源隔离天然独立;
- 为 DLA 和 GPU 各自创建独立 TensorRT Context。
- 内存与数据同步
- 注意:在 CUDA Context 之外,显存、Host 映射等资源也无法跨 context 共享;
- 切换 Context 时,显式
cudaMemcpyAsync()与cudaStreamSynchronize()确保数据同步与完整性。
- 并行执行
- DLA 上跑模型 H;
- GPU 上跑模型 A、B、C、D、E;
- 彼此互不干扰,独立抢占各自算力。
五、最终验证
- 7×24 h 连续压测:自 2025 年 4 月以来,未再出现任何死锁。
- 蝴蝶效应终成蝶:原本令人头痛的 DLA 隐晦死锁,反而催生出一套“安全气囊”式的多 context 并行机制——既排除了模型 A 的潜在越界风险,又保障了 DLA 与 GPU 资源的稳健协同。
六、结语
当我们在深度学习推理的微观世界里拨开层层迷雾,总会发现,看似偶然的卡死背后,往往是资源管理与并发调度的微妙博弈。通过多 Context 隔离,为 DLA 与 GPU 架起了一道“安全栅栏”,既兼顾了性能,又守护了系统的可用性——这,或许就是自动驾驶推理优化的下一块基石。
—— 致正在与 DLA、TensorRT、CUDA “暗礁”博弈的你