轻量化部署:Xavier设备低成本运行DeepSeek+QWQ大模型
在边缘设备上部署大语言模型一直被认为是算力密集型的’禁区’,但当我用一块Jetson Xavier AGX成功运行了DeepSeek-R1 14B和QWQ-32B模型时,推理速度稳定在 8 tokens/s (DeepSeek-R1 14B) / 4 tokens/s (QWQ-32B) 以上!本文将分享从环境配置到量化优化的完整方案,证明边缘设备同样可以成为轻量化AI的舞台。
一、硬件配置与挑战分析:
- 设备选型:NVIDIA Jetson Xavier AGX
- 核心参数:512核Volta GPU + 8核Carmel CPU / 32GB RAM / 32GB eMMC
- 系统环境:JetPack 5.1.3 (Ubuntu 20.04) / CUDA 11.4 / TensorRT 8.5.2
- 功耗模式:默认10W切换至MAXN模式
为什么选择DeepSeek & QWQ?
| 维度 | QWQ-32B | DeepSeek-R1-14B |
|---|---|---|
| 参数量 | 32B | 14B |
| 架构类型 | Decoder-Only(密集型) | MoE(混合专家,16选2) |
| 上下文窗口 | 训练支持32K | 原生支持16K |
| Xavier显存占用 | 20~22GB | 6~8GB |
| 推理速度 | 4.3 tokens/s | 8.7 tokens/s |
| 优势 | 长文本理解能力突出 工业领域知识深度优化 动态稀疏激活降低计算负载 |
代码生成能力领先 多轮对话响应快 MoE架构灵活适配多任务 |
部署三大难关
- 显存墙:FP16模型加载即需14GB+显存 → Jetson统一内存
- 架构差异:ARM平台与x86服务器的库兼容性问题 → Docker容器化
- 计算瓶颈:Token生成速度<5tokens/s时用户体验差 → 流水线优化
二、技术实现全流程拆解
阶段一:构建ARM适配的基础环境
核心挑战:NVIDIA Jetson Xavier的ARM架构与常规x86服务器存在三大差异:
- 指令集差异:ARMv8.2与x86_64的SIMD指令集不兼容(如NEON vs AVX512)
- 内存管理差异:Jetson采用CPU-GPU统一内存架构(UMA),与传统PCIe分体式显存管理模式冲突
- 软件生态差异:PyTorch等框架的ARM预编译包缺失关键算子支持
技术路线:
采用「容器化隔离+定制化编译」双轨策略:
- 硬件抽象层:通过 jetson-containers 项目预构建CUDA、cuDNN等核心组件的ARM64版本容器镜像
- 依赖解耦:针对JetPack 5.1.3的特定版本(CUDA 11.4 + TensorRT 8.5.2),使用镜像解决动态库符号链接问题
关键实现:
- 更新python版本:jetson-containers代码依赖Python 3.9(
functools.cache),需要将原有python3.8更新为python3.9版本
1 | sudo rm /usr/bin/python3 && \ |
- 安装jetson-containers:
1 | git clone https://github.com/dusty-nv/jetson-containers |
- 设置Docker Runtime:
修改/etc/docker/daemon.json配置,并指定default-runtime
1 | { |
重启docker服务
1
sudo systemctl restart docker
验证配置更新
1
sudo docker info | grep 'Default Runtime'
显示docker没有root权限:
阶段二:构建Ollama基础镜像
- 修改Dockerfile
修改jetson-containers/packages/llm/ollama/Dockerfile为以下内容
1 | #--- |
- 构建镜像
1 | jetson-containers build ollama |
- 验证构建镜像
1 | docker images | grep ollama |
阶段三:模型下载 & 推理
- 进入Container环境
1 | jetson-containers run --name ollama $(autotag ollama) |
- 模型下载
1 | ollama pull qwq:latest |
- 模型推理验证
1 | ollama run qwq:latest |
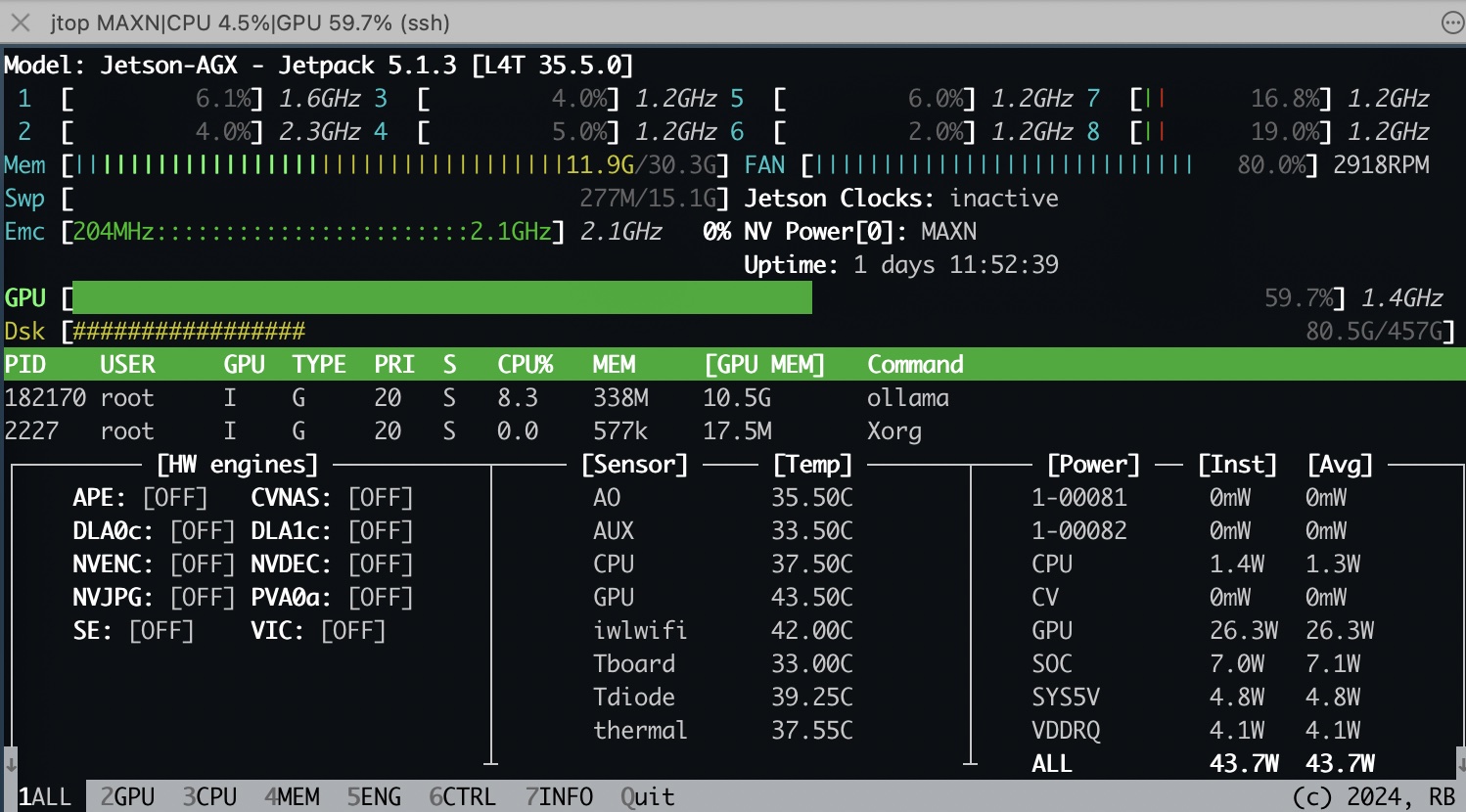
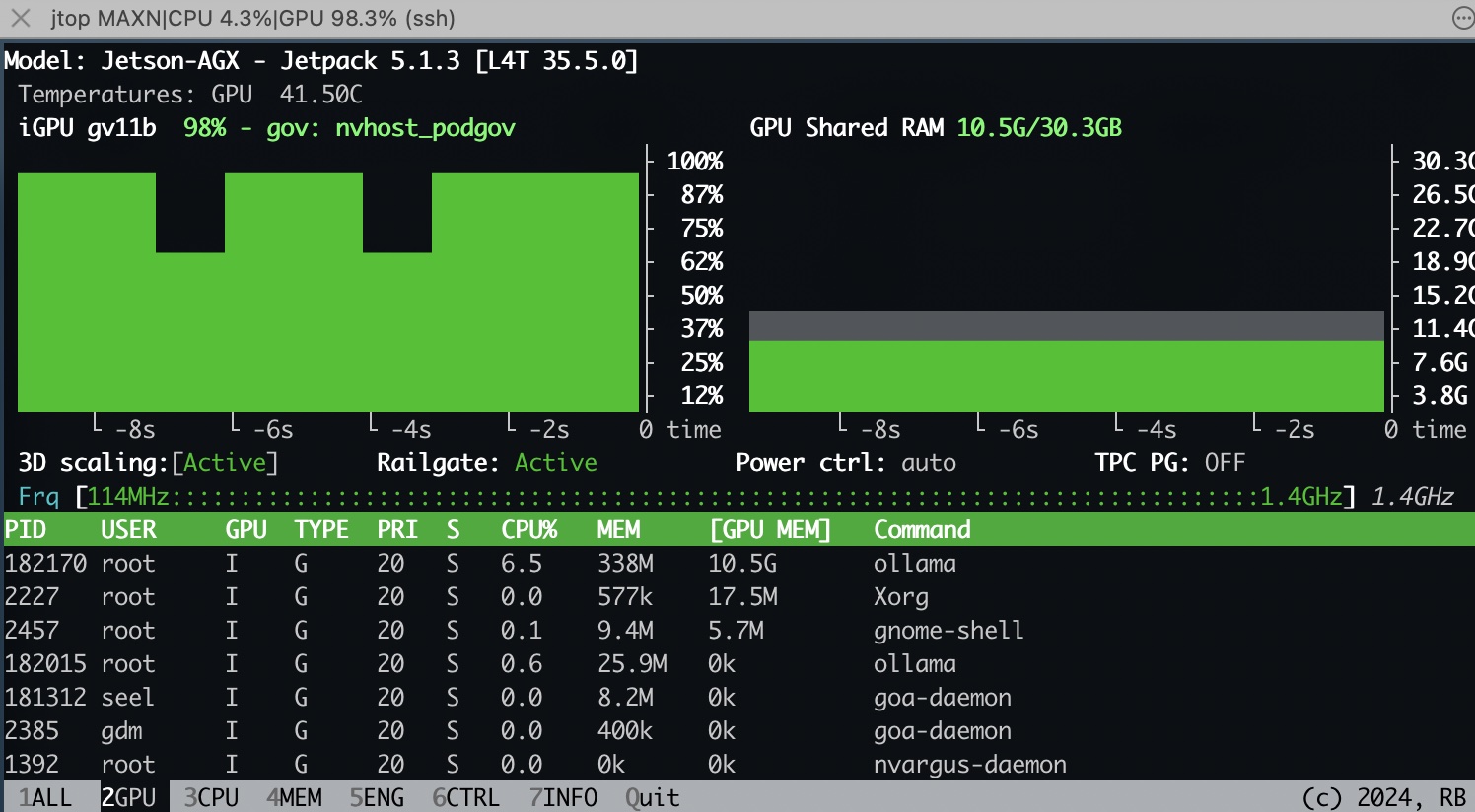
查看GPU使用率
1
jtop
jtop安装:
2
sudo systemctl restart jtop.service
阶段四(可选):K3S部署与服务搭建
待补充
三、性能实测:数据不说谎
模型对比实验
| 模型 | 显存 | 待机功耗 | 运行功耗 | prompt eval rate | eval rate |
|---|---|---|---|---|---|
| deepseek-r1:14b | 10.5G | 5.1w | 43.7 w | 144.21 tokens/s | 8.11 tokens/s |
| QwQ:32b | 21.1G | 5.4 w | 47.6 w | 6.04 tokens/s | 3.93 tokens/s |
deepseek-r1:14b
QwQ:32b
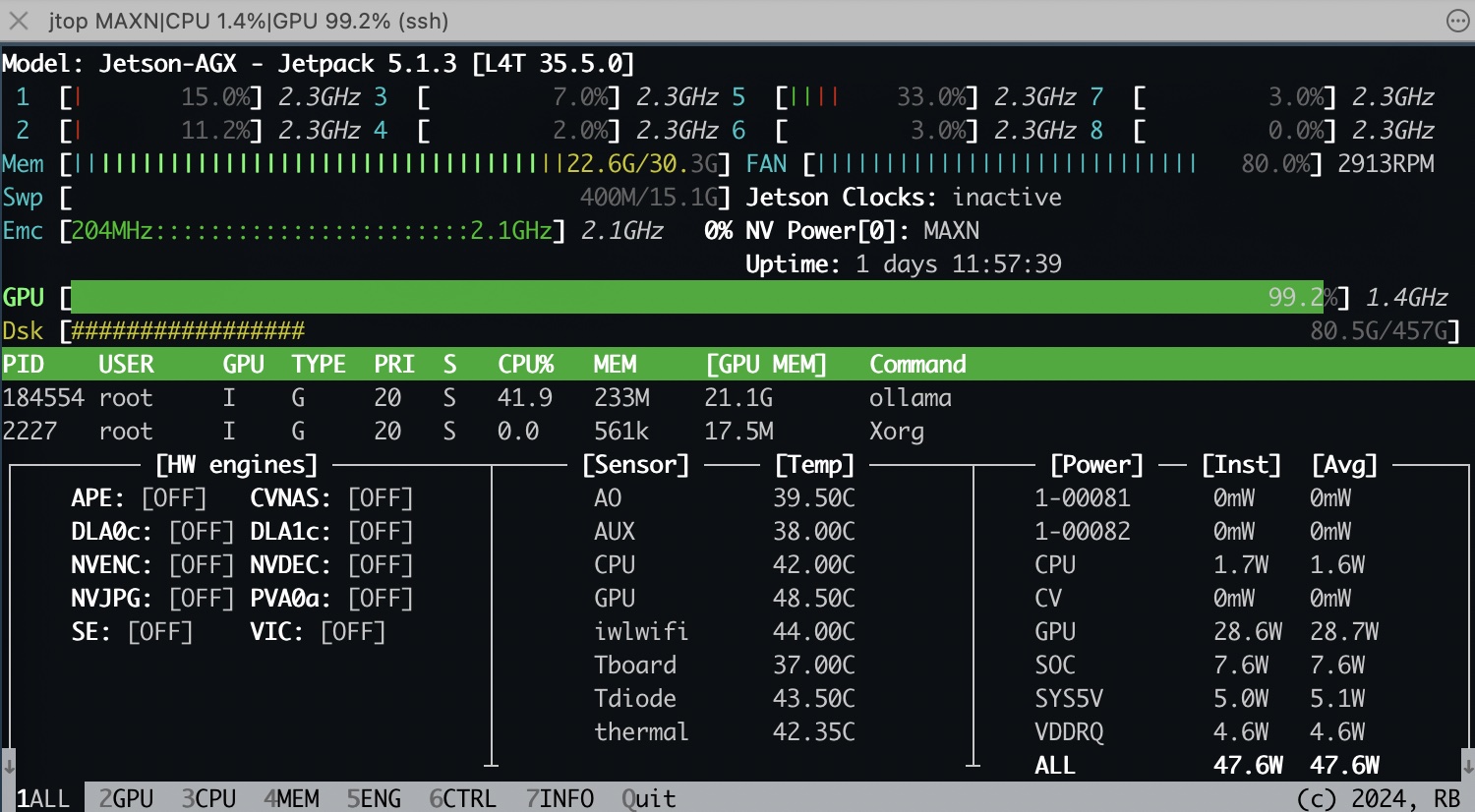
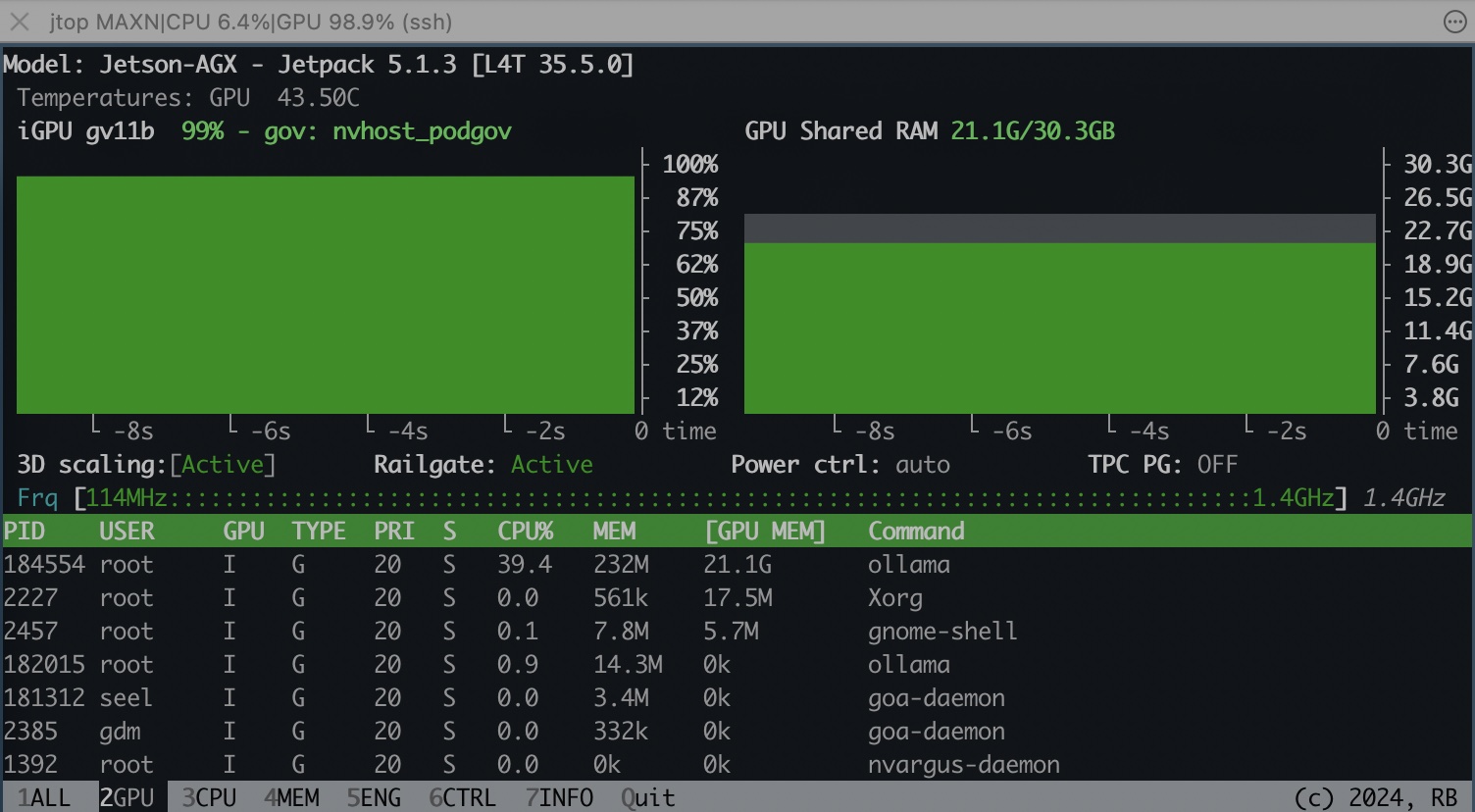
成本效益对比
| 方案 | 硬件成本 | 每月费用 | 延迟 | 数据出境风险 |
|---|---|---|---|---|
| 云端API | ¥ 0 | ¥1600 | 200ms | 高 |
| Xavier本地 | ¥ 3000 | ¥18 | 20ms | 零 |
应用场景:这不是玩具,是生产力
案例1:openweb-ui知识库本地问答
待补充